The Center for Voice Intelligence and Security (CVIS) engages in developing,
deploying and securing technologies that tap into
the information-bearing capacity of human voice. It also engages in educational activities, including short-term courses for visitors, regular courses and training programs.
CVIS has expanded into five areas of research: Basic sciences for exploring human voice, Voice intelligence, Voice security, Multimedia in embodied AI systems and Quantum computing for all of the above.
Sponsors and Supporting Organizations
Voice Intelligence
The human voice carries an immense amount of information. Inherently, it carries information about the speaker. Further information -- both about the speaker, and the world as perceived and understood by the speaker -- is superimposed on it using language. Voice Intelligence is simply the process of distilling all of this information for use by machines -- largely computing machines with intelligence of their own.
Thus voice intelligence would involve technologies that range from discerning the speaker's physical, physiological, psychological and other aspects from voice (the science of profiling humans from their voice), to understanding the content of human vocalizations and speech in various contexts.
There are myriad applications of voice intelligence technologies. Information derived from voice can be used to enable healthcare applications, security applications, personal convenience applications, communication enhancement for retail, entertainment, interactive robotics, and much more, including manufacturing control. Our projects cover some of these application areas, and we invite collaborations on starting new ones with our group at CVIS. More information about these, including who to contact, can be found on this website .
Voice Security
Technologies for voice security focus on protecting information in voice data and securing voice communications. Research areas under voice security include voice encryption, voice steganography, voice transformation, voice synthesis, privacy preserving voice processing, anti-surveillance technologies and many more. Different subsets of these are used by different applications to protect the integrity, confidentiality, and availability of voice data within them.
As voice interfaces become more prevalent in devices ranging from smartphones to smart home devices, the importance of voice security continues to grow. There is a growing need for standards, guidelines, and laws relating to voice security, to protect individuals' privacy and ensure the responsible use of these technologies. We include specific technologies for these under Voice security as well.
You can learn more about CVIS projects related to voice security from this website .
Basic Research Exploring the Human Voice

For all the science of the past centuries, human voice still remains unexplored from several perspectives. It is also not fully understood from an information-theoretic perspective. Its effects are not fully documented, its range is unknown, its variations are not categorized, its relationship to the DNA, to anthropometric entities, to the bones, skull structure and facial structure etc is not fully explored, its evolution over time, its variation through ethnic divisions is not mapped... this list goes on. Draw a graph with an unlabeled x-axis and a y-axis labeled "variation," and we find that for anything that is not relatable to a single speaker, with any label on the x-axis, there is little data to populate the graph.
At CVIS we are finding ways to explore some of these unknowns. There are no specific applications that are targeted here. This is fundamental research for the furtherment of science and scientifc knowledge. Some of our findings are documented on this website.
Multimedia in Embodied AI

We are building physical embodiments of AI from ground-up in our lab. These embodiments are designed and 3-D printed in our lab. Our focus in on incorporating our advnaced technologies for interpreting the human state from voice into these embodiments, so that they can understand humans and respond to them with much greater acument than humans themselves can. For example, our technologies for gauging emotion and personality, and the physical and mental state of speakers from their voice allow our embodied AI systems to generate responses and expressions that are most appropriate for the situation. To enable this, we also delve into multimedia generative AI systems, re-architecturing them to synergize with our desired goals for embodied AI.
In all of this, there is indeed a seamless integration of basic robotic architectures and principles. Many fundamental problems in robot motion and expression must be revisited. And the highly expanded range of motion that is now desirable for a vastly more intelligent AI system's embodiment leads to deeper explorations into hardware architectures and computing platforms. The boundaries between the areas of multimedia processing, generative AI, embodied AI and advanced computing paradigms and architectures are becoming increasingly blurred, giving rise to an area that we have labeled "Multimedia in embodied AI systems."More about our work in this area is documented on this website
Quantum Computing
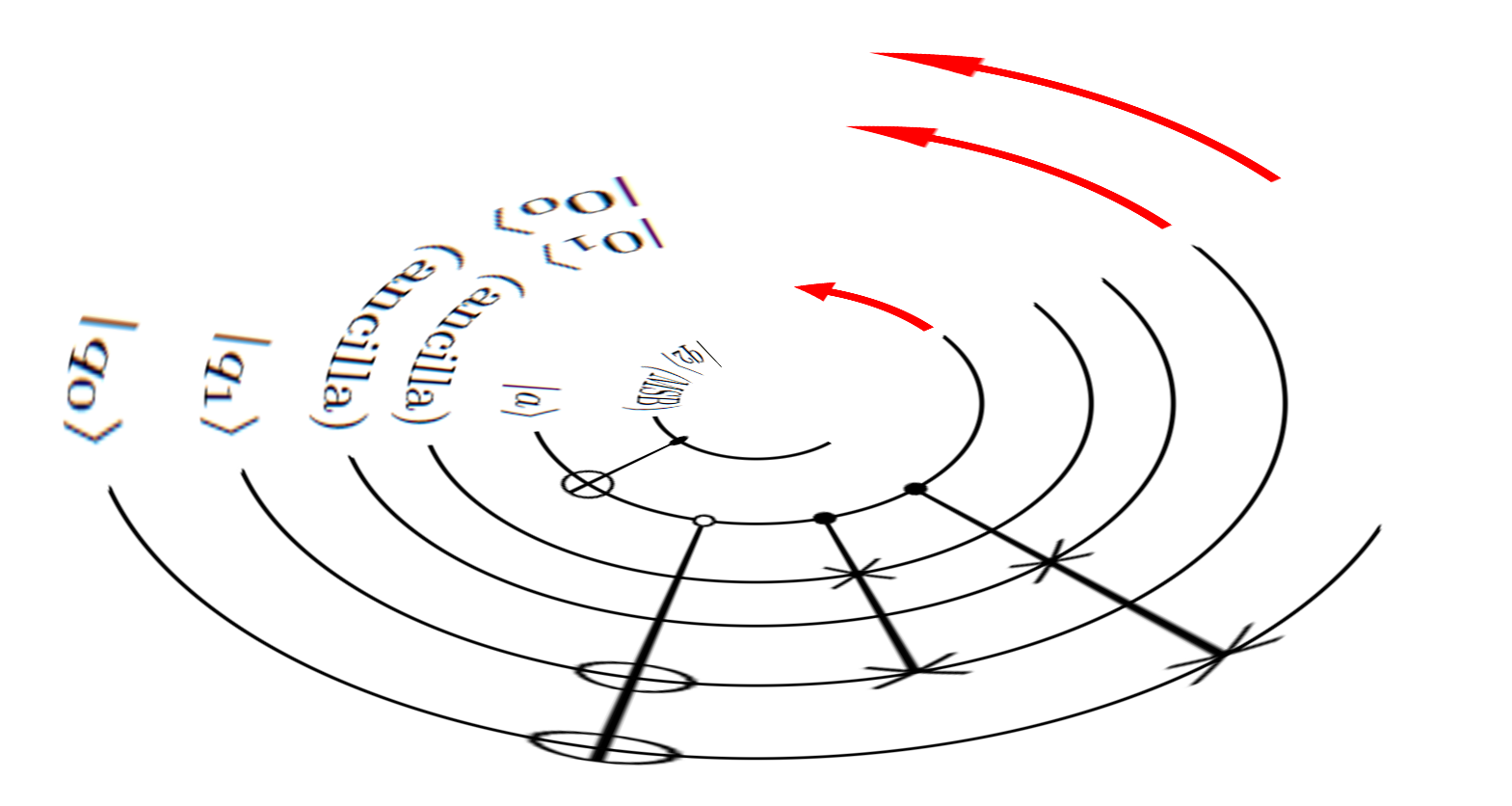
When it comes to quantum computing, we have been hammering in the pegs for our tent in this new terrain for the past four years. Now we are entering the area, having built up our comfort zone and defined our goals. Collectively, we have taught and taken classes in quantum computing for several years now. Currently, our focus is on building quantum circuits for supporting learning in AI systems. Our goal is to build more powerful systems for multimedia-based human understanding, and its translation to physical motion and expression rendering in embodied AI systems. One day, a lot more will happen when we have more access to real quantum computers. Much of our work entails simulations and quantum circuits that are designed to give a desired level of quantum advantage in classical implementations of our algorithms.
More about our work in this area is documented on this website