Voice Security
Protecting our voiceprints
We make judgments about people from their voices all the time. Very soon, machines will analyze our voices and know more about us than we do -- because they will be able to make much finer-level, much more accurate judgments about us (and what influences us at the time of speaking) from our voice.Voice is a potent biometric -- just like fingerprints and DNA. However, unlike fingerprints and DNA, it carries information about us, about our environtment and other factors at the time of speaking. Given the uniqueness of our voice, and given that it is possible to derive an ever-increasing amount of information from it, the question to ponder is: how will we protect our voices in the future? Will it be possible to de-identify voices? From what we know by now, that is akin to asking ``can we remove DNA from blood?'' If not, then what are our options?
Our work on voice security focuses on exploring and developing some viable options, while at the same time building technologies for preventing the abuse and misuse of voice if these options prove to be insufficient. Some of our work is described on this page.
Privacy preserving voice processing

(Click all images on this page to enlarge) Privacy-preserving voice processing is focused on safeguarding personal voice data from unauthorized access. It employs many sophisticated techniques such as homomorphic encryption, differential privacy, and secure multi-party computation to securely process voice data. Homomorphic encryption allows operations directly on encrypted data, delivering results that, when decrypted, match operations as if performed on the raw data. Differential privacy offers statistical accuracy in data analysis without revealing information specific to individuals. Secure multi-party computation permits multiple parties to compute collective data results without revealing individual inputs. These methods, combined with voice biometrics and anonymization techniques, ensure that voice data can be processed and analyzed without compromising the privacy of the speaker. |
Publications
ApplicationsPrivacy preserving voice processing is vital in securing the confidentiality and integrity of applications such as voice assistants, call centers, and telecommunication services. |
Technologies for adversarial robustness

Adversarial attacks involve intentional alterations in the input data, aimed at causing specific types of erroneous outputs that suit the purposes of the adversary. In systems that deal with speech, these attacks can manipulate speech signals subtly, deceiving Automatic Speech Recognition (ASR) systems, speaker recognition models, or voice biometric security systems into producing desired (wrong) outputs. Technologies for adversarial robustness are focused on counteracting these threats. Adversarial robustness focuses on enhancing system defenses via techniques such as adversarial training, which augments training data with adversarial examples, and defensive distillation, a process that makes models less sensitive to input perturbations. Incorporating gradient masking or reducing gradient interpretability can also fortify against attacks. Machine learning models such as Generative Adversarial Networks (GANs) can be employed to generate robust synthetic speech data. |
Publications
ApplicationsAs the adoption of speech processing systems like smart voice assistants and voice-controlled IoT devices increases, ensuring their adversarial robustness becomes paramount to maintain trust and ensure secure, accurate operations.
|
AI systems for transformation, generation and detection of synthetic voices
Synthetic voice generation models generate human-like speech from text by learning from vast quantities of voice data. These models create an audio waveform, matching human speech patterns and tones, thereby generating synthetic voices that closely resemble human speech. While synthetic voice technologies offer significant benefits in domains like entertainment, virtual assistants and accessibility, they also present challenges. Their capacity to create realistic, human-like speech has led to the rise of 'deepfakes' -- synthetic media where a person's voice is replicated with high accuracy. Such technology can be misused for misinformation, fraud, or cybercrime, making an individual appear to say things they never did. This raises significant privacy and security concerns. We are working to develop technologies that can detect synthetic speech. |
Publications
ApplicationsThese tools would help verify the authenticity of audio content, combat the misuse of deepfake technologies, and uphold trust in digital communications.
|
Voice steganography

Steganography is the art of hiding information. In cryptography, information is hidden in plain sight -- it is encrypted and often impossible to decrypt without the right keys. In steganography, the very existence of hidden information is hidden. We are using AI techniques to find ways to hide information imperceptibly in voice signals, and also for steganalysis -- to detect hidden information in voice signals.
|
Publications
ApplicationsThese tools would help verify the authenticity of audio content, combat the misuse of deepfake technologies, and uphold trust in digital communications.
|
Voice authentication

Voice authentication leverages the biometric characteristics of an individual's voice to verify a speaker. It serves as a secure and convenient alternative to traditional passwords and PIN-based systems, and is currently used in banking, customer service, smart homes, and mobile device security in conjuction with other biometric authentication methods, such as fingerprint and face recognition. Voice authentication systems work by extracting features from the user's speech that carry the essence of a speaker's unique identity. Like the voice signal, these features comprise unique voiceprints for speakers. During authentication, the system compares the user's voice against voiceprint-generated information to verify their identity. While voice authentication provides ease of use and increased security, it's not foolproof. Background noise, illness, aging, and advanced synthetic voice technologies can potentially affect its accuracy. Furthermore, privacy concerns arise regarding the storage and potential misuse of biometric data, necessitating robust data protection measures. At CVIS, we continue to work on cutting-edge biometric security technologies for voice authentication.
|
Publications
ApplicationsWhen voice verification systems becomes completely accurate and secure, some procedures may become much more efficient, easy and convenient, such as entry through airports and secure areas.
|
Benchmarking voice clone detectionBenchmarking Voice Clone Detection is an advanced AI evaluation methodology designed for organizations and security professionals combating audio fraud and deepfake threats. Understanding the necessity of distinguishing between authentic and synthetic speech, this tool rigorously tests systems for detecting voice cloning with precision and speed. Unlike conventional audio analysis techniques that rely on static, rule-based detection, our product leverages extensive speech synthesis datasets and dynamic AI testing. This unique approach ensures superior performance against evolving cloning technologies, providing a robust defense in the ever-changing landscape of audio security. Unlike conventional audio analysis techniques that rely on static, rule-based detection, our project leverages extensive speech synthesis datasets and dynamic AI testing. This unique approach ensures superior performance against evolving cloning technologies, providing a robust defense in the ever-changing landscape of audio security.
|
Publications
ApplicationsThis technology is useful for detecting voice deepfakes.
|
Benchmarking spliced speech detectionOur work on benchmarking spliced speech detection supports a comprehensive validation methodology crafted for forensic analysts and content verification teams who need to authenticate audio recordings and detect tampering. It addresses the imperative of identifying spliced segments to ensure the integrity of speech content. Unlike general-purpose audio editing detection methods, our solution employs fine-grained acoustic-phonetic analysis and prosodic modeling. This differentiation offers unmatched accuracy in pinpointing subtle edits, helping maintain evidentiary standards and trustworthiness in legal, security, and media applications.
|
Publications
ApplicationsThis technology is useful for detecting voice deepfakes.
|
Verification at the level of basic units of sound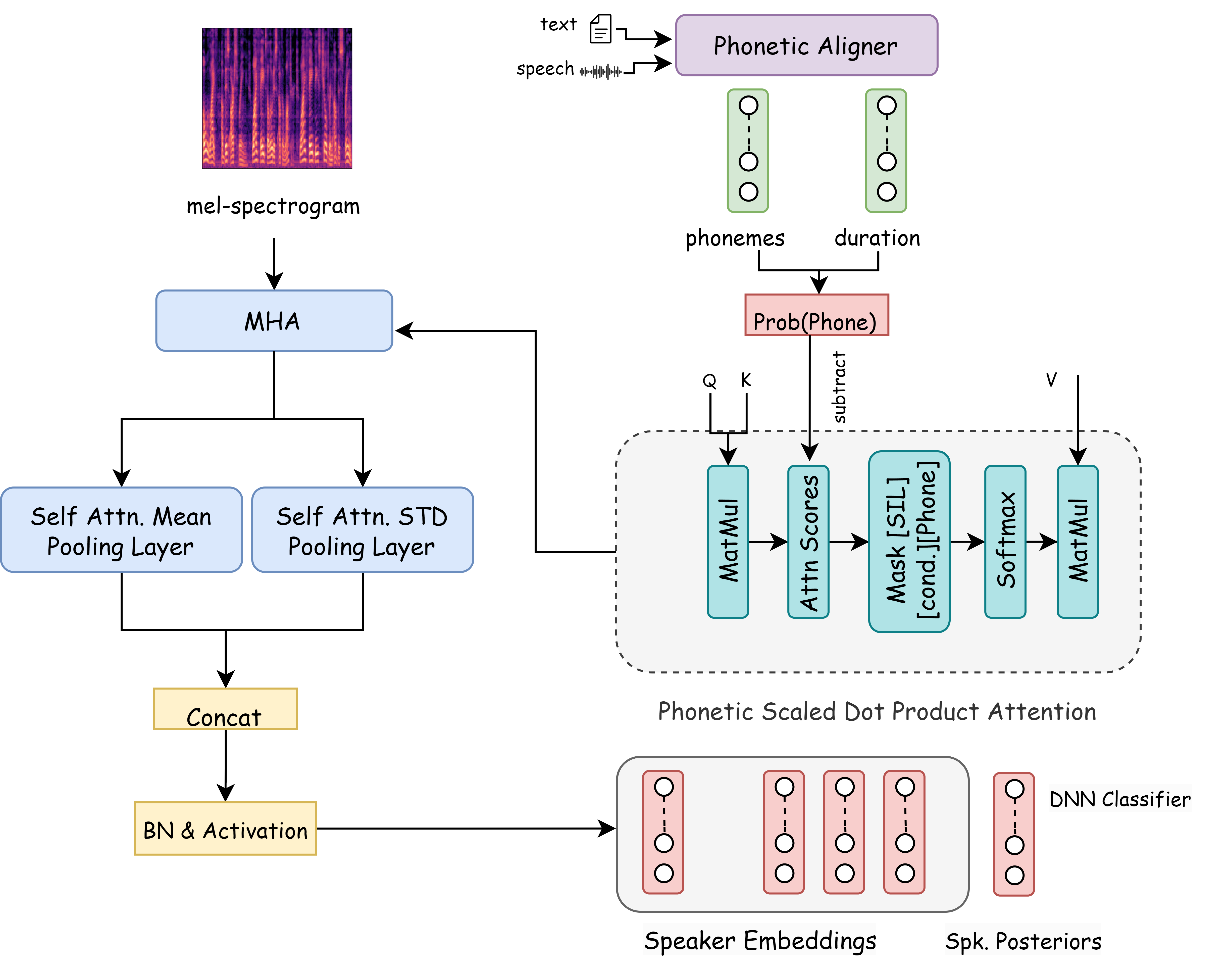
Traditionally, speaker verification systems focus on comparing feature vectors, overlooking the speech’s content. However, this paper challenges this by highlighting the importance of phonetic dominance, a measure of the frequency or duration of phonemes, as a crucial cue in speaker verification. In this we introduce a novel Phoneme-Debiasing Attention Framework (PDAF) which integrates with existing attention frameworks to mitigate biases caused by phonetic dominance. PDAF adjusts the weighting for each phoneme and influences feature extraction, allowing for a more nuanced analysis of speech. This approach paves the way for more accurate and reliable identity authentication through voice. Furthermore, by employing various weighting strategies, we evaluate the influence of phonetic features on the efficacy of the speaker verification system. |
Publications
ApplicationsPDAF refines feature extraction and reduces biases inherent in traditional systems. This innovation can improve security in applications like biometric authentication for banking, access control, and secure communications. Additionally, it holds potential in forensic voice analysis, enabling more reliable identification in legal and investigative contexts, and in personalized voice services, ensuring more precise user recognition in smart devices and virtual assistants. |
Verification using foundation models for descriptive profiling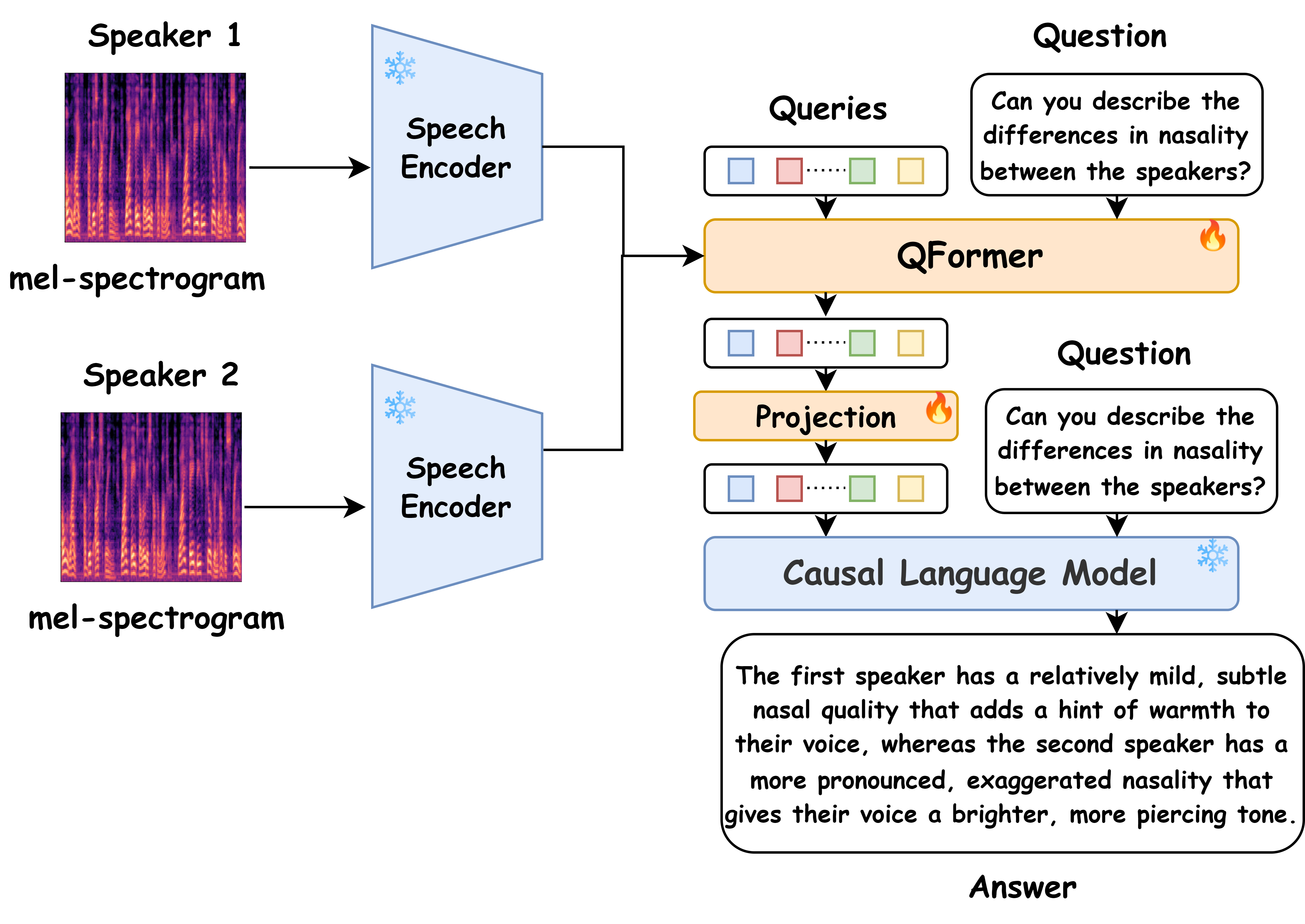
This work creates a new kind of speaker verification model -- one that reasons for the task. Traditional speaker verification systems often lack transparency and fail to offer insights beyond basic voice matching. We have created CoLMbo-SV, a novel speaker language model that compares two speech inputs, analyzing both voice quality and inferred personality traits. A key innovation of CoLMbo-SV is its explainability, addressing the limitations of existing models in paired speech analysis. By incorporating a Q-Former module and a large language model (LLM), CoLMbo-SV enhances precision and interpretability, setting a new standard for reliable and explainable speaker verification. To the best of our knowledge, CoLMbo-SV is the first speaker language model capable of providing such comprehensive comparative assessments between speakers, setting a new standard for reliable and explainable speaker verification. |
Publications
ApplicationsThis technology's precision and interpretability make it ideal for use in high-security sectors such as banking and enterprise authentication, where reliability and transparency are critical. In customer service, CoLMbo-SV can support tailored user experiences by identifying and verifying speakers while offering insights into communication styles. Additionally, its advanced paired speech analysis capabilities can benefit recruitment processes by enabling voice-based assessments and comparisons of candidates. Its explainability also makes it a valuable tool for regulatory compliance in industries requiring auditable AI systems.
|