Multimedia in Embodied AI
Responsive multimedia: Foundations for human-AI communication
When it comes to human-AI communications, there is a catch. With the technologies of today, AI systems are poised to understand humans better than humans do! If we don't perceive what they perceive, how then can we teach them to react appropriately?
A major aspect of embodied AI systems is the physical manner in which they are expected to communicate with humans -- through expressions, motion, gestures ("body" langauge), sound, image sequence projections, touch and in many other ways. As in human-human interactions, the finer nuances of these "expressions" tend to enrich the interactions and often deeply permeate into human perception and psyche. In human-AI iteractions, simply emulating the finer nuances of human responses as exemplified by standard multimedia (training) data won't suffice. We need to think and search beyond the obvious and build AI systems to respond with superfine acuity, and for that we need to build yet other systems that are capable of generating such multimedia-based AI responses.
Our work pushes the envelope, exploring cutting-edge ideas in generative AI for this purpose. This applies to all multimedia modalities -- audio, video, images and text -- separately and jointly. Some of this work is described below.
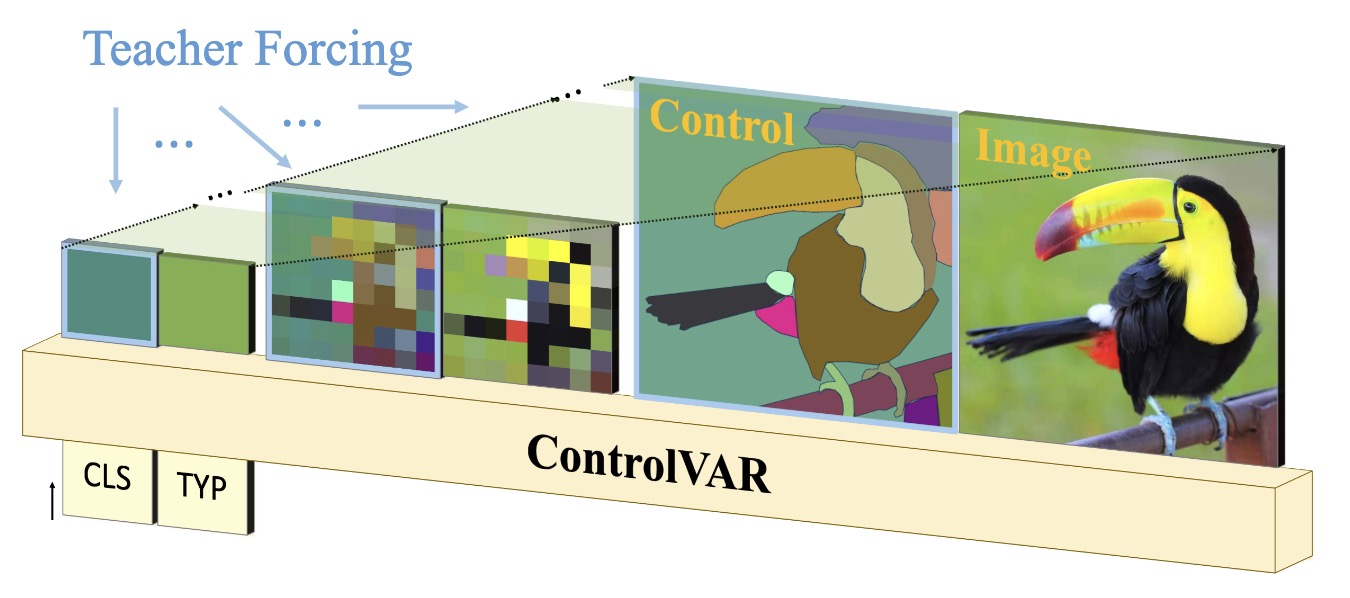
Responsive autoregressive audio-image generation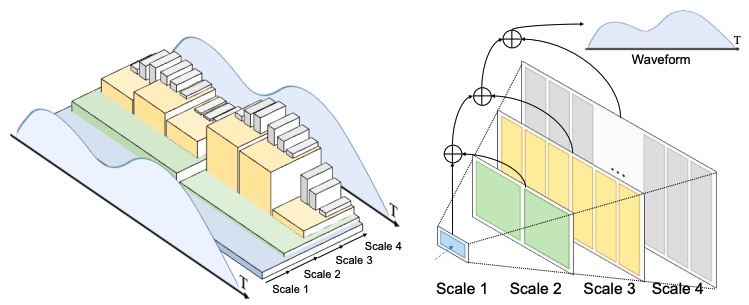
 (Click on all images on this page to enlarge)
(Click on all images on this page to enlarge)
Autoregressive (AR) image/audio generation has achieved notable progress and demonstrated promising performance recently. The current advanced image/audio generation paradigm typically requires a pre-trained image tokenizer that encodes the image into a more compact latent space, where an AR generator, e.g. transformers, is leveraged to model the latent distribution, for both efficiency and effectiveness in generation. |
Publications
CodeGithub code repository: Advanced tokenizer training framework for AR/VAR image generation; Introducing PQ to shorten the token length of VAR modeling to half. Github code repository: Fast autoregressive audio generation with next-scale prediction. |
Unified speech enhancement and editing with conditional diffusion models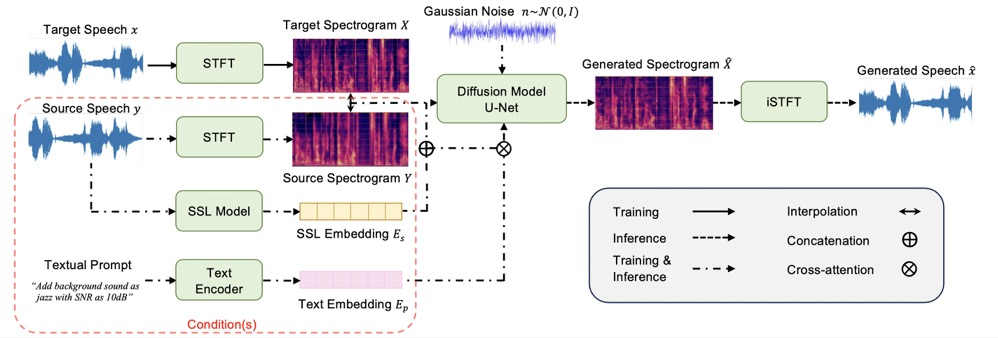
In this work we have built a unified Speech Enhancement and Editing (uSee) framework with conditional diffusion models to enable fine-grained controllable generation based on both acoustic and textual prompts. This model achieves superior performance in both speech denoising and dereverberation compared to other related generative speech enhancement models, and can perform speech editing given desired environmental sound text description, signal-to-noise ratios (SNR), and room impulse responses (RIR). |
Publications
CodeGithub code repository: Coming up. |
Continual learning paradigms for AI systems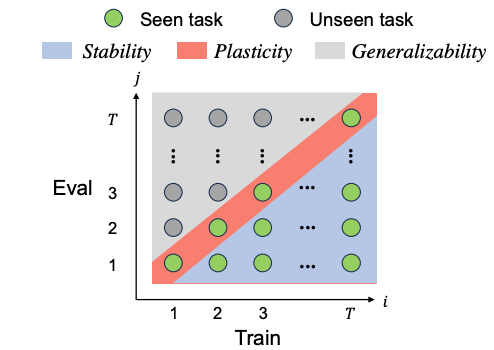
Continual learning paradigms have transformative applications in developing AI systems capable of adapting to evolving tasks and environments without losing previously acquired knowledge. Existing continual learning metrics neglect the overall performance across all tasks, and do not adequately disentangle the plasticity versus stability/generalizability trade-offs in the model. We have created the Dual-transfer Matching Index (DMI) as a unified metric to evaluate all three properties of a continual learning system: stability, plasticity and generalizability. By employing the proposed metric, we demonstrate how introducing various knowledge distillations can improve these three properties. |
Publications
CodeGithub code repository: Coming up. ApplicationsThis work has significant implications for industries like autonomous vehicles, where models must learn from new driving scenarios while retaining prior safety protocols. In personalized healthcare, continual learning enables AI systems to update patient models with new data while preserving historical insights, enhancing diagnostic accuracy and treatment planning. Additionally, adaptive AI in education can refine personalized learning paths based on ongoing performance, while in cybersecurity, it can improve threat detection by integrating emerging attack patterns without compromising prior safeguards. The DMI's ability to evaluate stability, plasticity, and generalizability ensures robust, adaptive, and reliable AI systems across these applications. |
Embodied AI
Building the robots
Multimedia foundation models -- enhanced versions of the phenomenal language models of today -- are undoubtedly more knowledgeabe than humans. They may not be more sensible, but they are certainly more knowledgeable. They can be prompted and they respond, and both the prompts and responses can be cast in multimedia format, including human voice. It is a natural next step to integrate these advanced AI models into physical robotic forms, and truly a joy to see these forms "come alive." However, serious problems remain to be solved in this context -- both in the robotic domain, and in the multimedia-based interaction domain. Today, the boundaries between these areas of research have become blurred and almost vanished. With our focus on integrating our voice and multimedia technologies into these embodied AI forms, we also necessarily have to revisit and innovate in the mechanical and machine learning aspects of robots. We are building robots from ground-up in our lab, and equipping them with specialized sensors that are optimal for our technologies. Our human-AI interaction research is then based on these platforms. . When it comes to human-AI communications, there is a catch. With the technologies of today, AI systems are poised to understand humans better than humans do! If we don't perceive what they perceive, how then can we teach them to react appropriately?
Wheeler

Wheeler was built by Kelsey Joseph Harvey, in collaboration with General Robotics. Wheeler is a cornerstone of General Robotics' comprehensive research initiative in Embodied AI, representing our wheeled platform implementation. Working in parallel with our ROVER quadruped platform, Wheeler demonstrates how our AI technologies can adapt to and leverage different physical embodiments while maintaining consistent core capabilities across platforms.
Wheeler serves as a key platform in our broader Embodied AI initiative wihich includes testing and validation of cross-platform AI capabilities, physical manipulation tasks in real-world environments, computer vision integration with acoustic sensing, multi-modal learning and adaptation, real-time decision making and planning and development of transferable AI skills across different robot embodiments. |
Publications
PatentBeing filed. ApplicationsEmbodied AI extends the capabilities of artificial intelligence into physical spaces, enabling machines to interact with the world through sensory perception, movement, and real-world decision-making. There are myriad applications for embodied AI in general, the range includes robotics for manufacturing and logistics, robotic surgical assistants and rehabilitation devices in healthcare, from drones to self-driving cars in autonomous vehicles etc. Embodied AI is integral to fields like space exploration, where robots equipped with physical and cognitive skills perform tasks in extreme and inaccessible environments. Wheeler's application is in personal task areas for humans, such as personal caregiving, personalized teaching, chores, conversation, emotional support etc. |
Secure AI
Adversarial robustness for AI systems that process multimedia
All AI systems must be secure against adversarial attacks. We are experimenting with a plethora of techniques for this. Some are described below.
Adversarial robustness techniques for multimedia modalities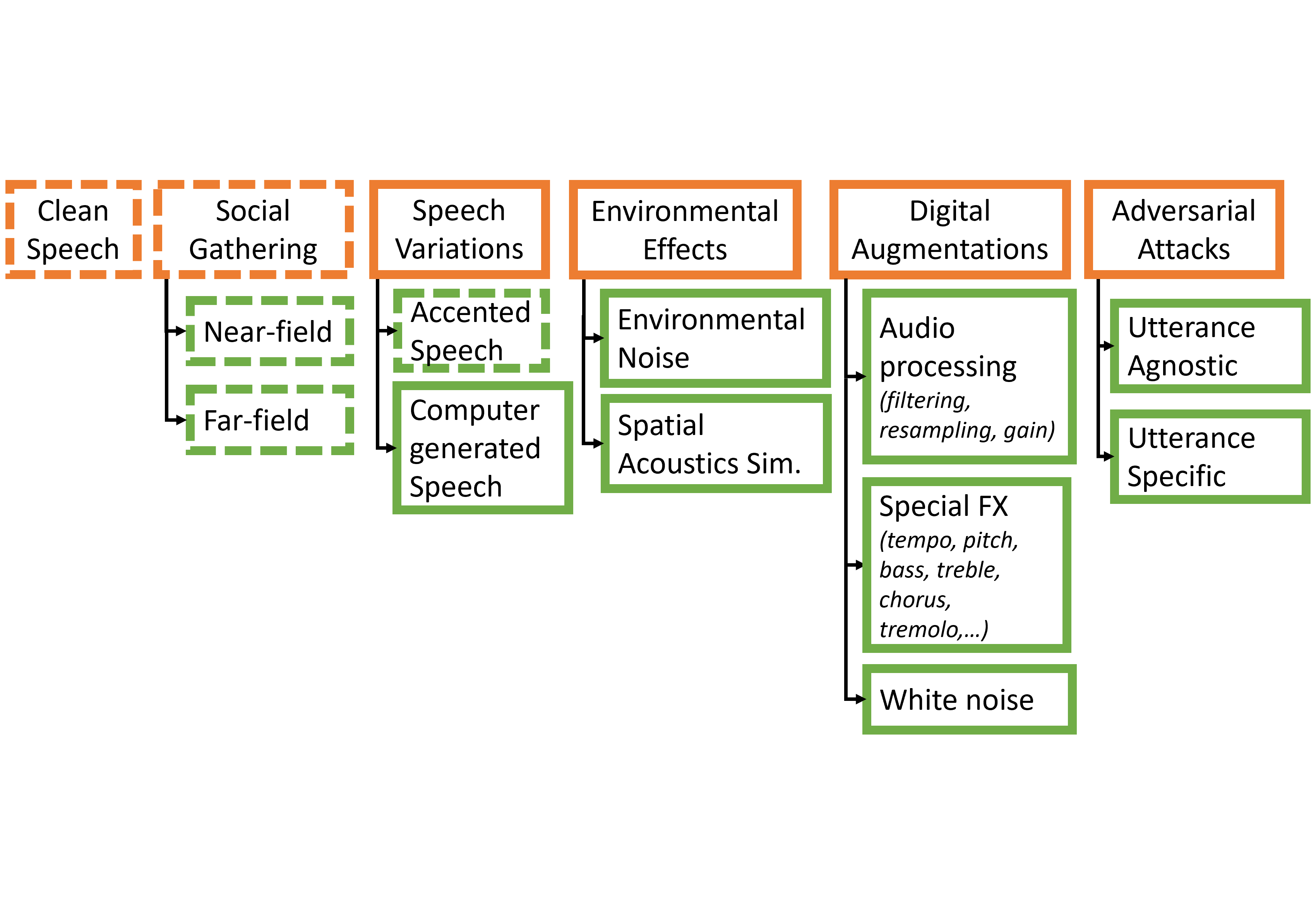
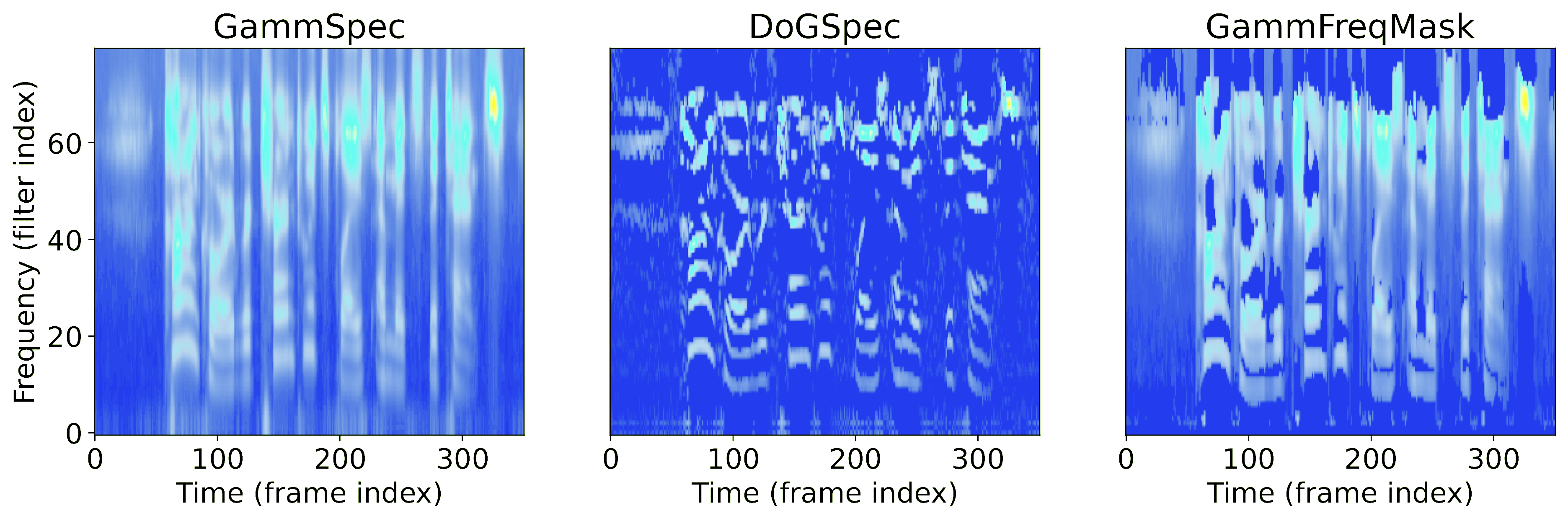
In this project we are developing techniques for measuring and enhancing the robustness of AI models to corruption, including adversarial attacks. Our work leverages biologically motivated neural network architectures and features that enhance robustness. For speech specifically, we have developed Speech Robust Bench, a comprehensive robustness benchmark for ASR. Our systems include self-consistent activation (SCA) to address the critical challenge in deep neural networks: vulnerability to adversarial perturbations. By introducing fixed inter-neuron covariability patterns, SCA enhances the robustness of DNNs to adversarial attacks without compromising accuracy on natural data. |
Publications
CodeComing up. ApplicationsThis innovation has promising applications in domains where reliability is paramount. In autonomous vehicles, SCA-enhanced DNNs could better resist adversarial attacks aimed at deceiving image recognition systems, ensuring safer navigation. Similarly, in biometric security, they could fortify voice or facial recognition systems against spoofing attempts. The improved generalization offered by SCA layers also makes them valuable in healthcare AI, where adversarial robustness is critical for maintaining accuracy in diagnostic tools under diverse and unpredictable conditions. This biologically inspired approach provides a pathway for deploying DNNs in high-stakes real-world scenarios with greater confidence. |
Understanding and Reasoning about the Environment Around Us
Audio understanding and reasoning
The internet hosts an extensive collection of user-uploaded audio recordings with unstructured metadata, featuring human speech, sounds, and music. These recordings are invaluable for understanding human history, culture, and preferences. By training machine learning models on millions of examples, we can create general-purpose representations to catalog and search this data. Recent research uses language supervision to develop these representations, leveraging multimodal encoders and Large Language Models (LLMs) to perceive, analyze, and reason about audio. These Audio Foundation Models excel in tasks like text-based retrieval, captioning, generation, and question-answering, showing early promise in audio understanding and reasoning. Our work addresses the entire spectrum of building such Audio Foundation Models, from learning methods to development and evaluation. Some of our key contributions in this field are listed below.
Learning methods for audio foundation models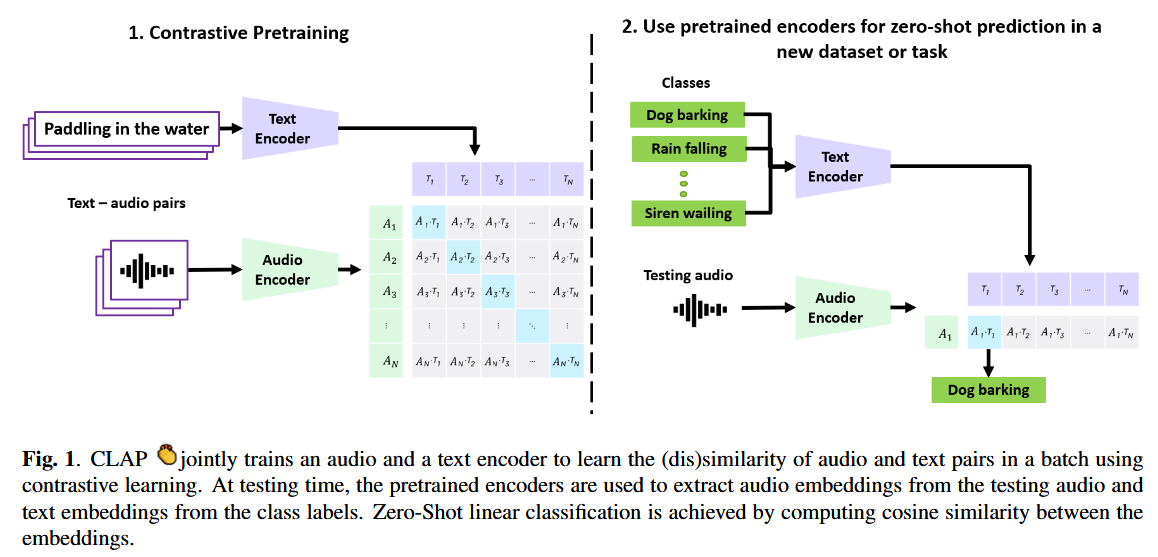

We explore learning audio foundation models through the lens of language. We propose Contrastive Audio-Language Pretraining (CLAP) to learn joint audio-text representations. Once trained, the model can enable applications like zero-shot classification, text-to-audio retrieval, and audio-to-text retrieval. To support open-ended tasks like audio captioning and audio question answering, we introduce Pengi, an Audio Language Model that leverages Transfer Learning by framing all audio tasks as text-generation tasks. Combining CLAP and Pengi, enables building an audio system that can perceive or understand multimodal input, and generate natural language responses. |
Publications
CodeApplicationsBy bridging acoustic signals with textual representations, these learning methods equip embodied agents to interpret environmental audio cues and communicate them in natural language. They also support open-ended tasks—like audio captioning and question answering—that allow an embodied AI to describe and reason about its auditory surroundings in real time. By combining Contrastive Audio-Language Pretraining (CLAP) and Pengi, robots or intelligent systems can seamlessly integrate multisensory perceptions and produce language-based responses, enabling richer interaction with the physical world. |
Adaptation methods for audio foundation models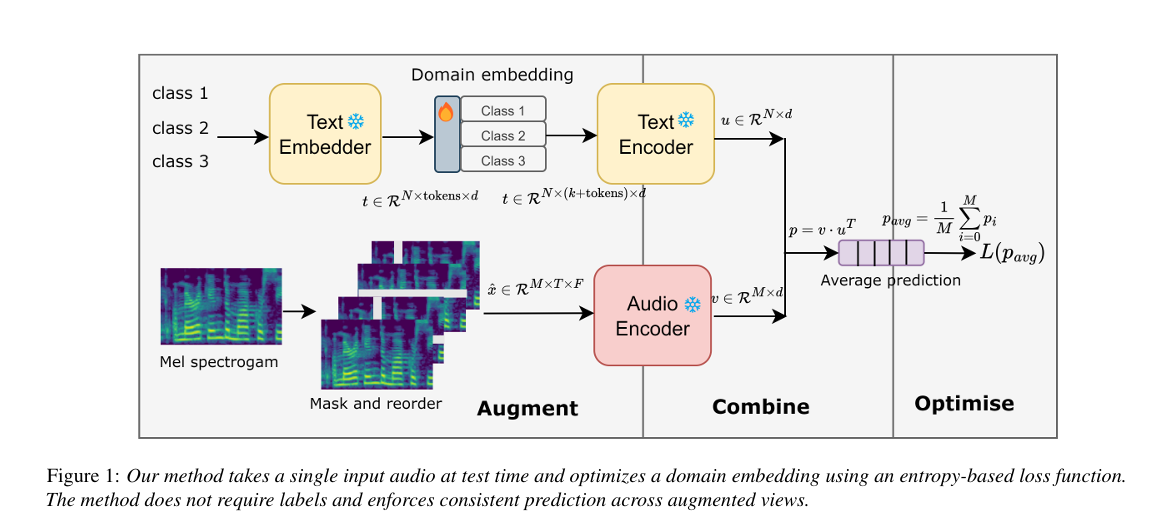
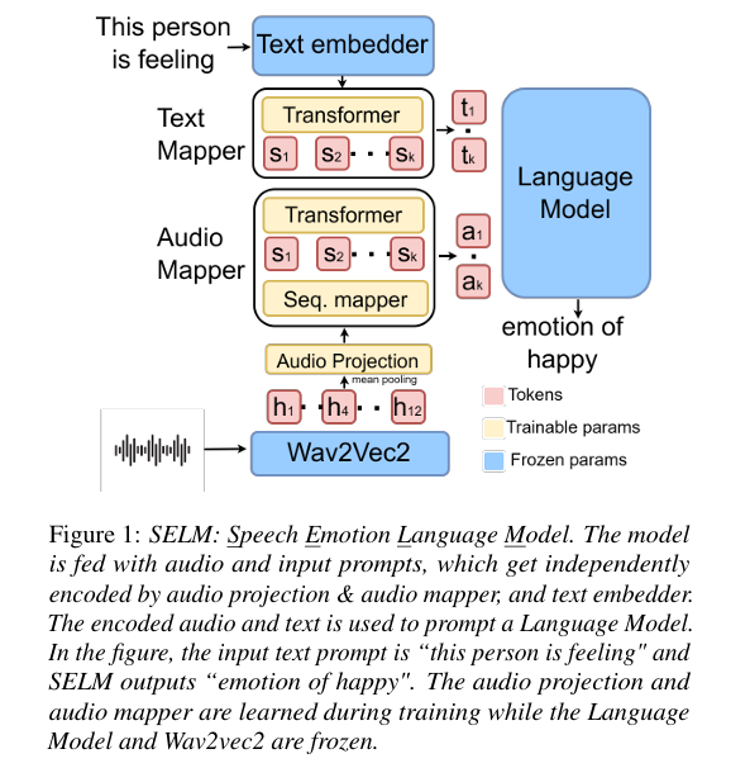
Audio foundation models (AFMs), though trained on millions of audio-text pairs, show near random performance on out-of-distribution/domain data. With this as backdrop, we are looking into adapting audio foundation models across different compute and data budgets. We have developed a test-time adaptation strategy for contrastive audio-language models, using unlabelled audio to learn soft tokens by minimizing entropy across different views. We are exploring few-shot learning scenarios with Pengi, focusing on achieving performance improvement with selected parameter updates. In this work we have also developed a method to counter missing modality at training time, allowing AFMs to be trained with a single modality or with generated data. |
Publications
CodeComing up. ApplicationsThis technology has real-life applications in improving the adaptability of audio foundation models for tasks like speech recognition in diverse accents, sound event detection in noisy environments, and audio captioning for accessibility tools. By enabling these models to perform well with limited data, varying compute resources, and missing modalities, it can advance fields like assistive technologies, real-time language translation, and content moderation across different languages and audio conditions. |
Reasoning, evaluation metrics, and benchmarks for audio foundation models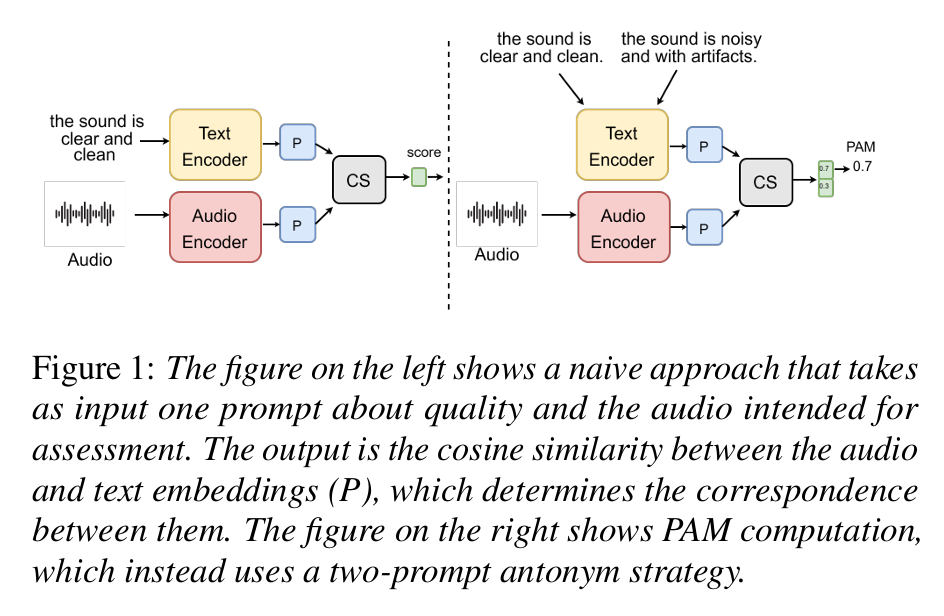
As audio foundation models (AFMs) scale, they begin to exhibit emergent abilities, with reasoning being the most impactful on downstream task performance.
Our work aims to enhance the reasoning capabilities of Audio Foundation Models (AFMs) and establish robust benchmarks for their performance. By leveraging emergent abilities, we explore innovative applications and metrics to address key challenges in audio processing. First, we demonstrate that AFMs can estimate audio quality without references using an antonym prompting strategy, paving the way for MelDiffusion, a diffusion model trained on spectrograms that achieves state-of-the-art audio generation quality. Building on this, we introduce audio entailment to evaluate deductive reasoning, addressing the reliance of models on Large Language Models (LLMs) by proposing a "caption-before-audio" strategy for improved audio-grounded logic. To measure comparative reasoning, we propose audio difference explanation, showing that smaller models can rival larger ones with optimized architectures and learning strategies. Finally, we introduce MACE, a novel audio captioning metric that incorporates audio information and achieves the highest correlation with human quality judgments. Together, these contributions form a unified approach to understanding, improving, and evaluating the reasoning and generative abilities of AFMs, supported by human-annotated datasets for comprehensive benchmarking. |
Publications
CodeComing up. ApplicationsThis technology has practical applications in areas like automated audio quality assessment for media production, enabling creators to ensure high-quality output without needing reference files. It can enhance accessibility tools by improving audio captioning for individuals with hearing impairments, offering more accurate and contextually relevant descriptions. In security and surveillance, the reasoning capabilities of Audio Foundation Models can assist in analyzing and interpreting complex audio environments, such as distinguishing critical sounds in noisy settings. Additionally, advancements in audio generation and entailment can support creative industries, enabling more realistic sound design and intelligent audio-based storytelling. These developments make AFMs valuable across media, accessibility, security, and entertainment domains. |