- The Race to Hide Your Voice. Wired, 1 Jun 2022. Magazine article
- Artificial Intelligence: HSBC Releases AI Campaign Featuring the Faces of Fraudsters. Adweek.com, 17 Nov 2022. News article
- HSBC and Wunderman Thompson put AI faces to fraudsters in global fraud prevention campaign. Marketing Beat, 18 Nov 2022. News article
- HSBC puts faces to 'invisible' fraudsters in global blitz. Decision Marketing, 22 Nov 2022. Article
- New and innovative HSBC campaign by Wunderman Thompson UK reveals the real faces of fraudsters. ArabAd, 21 Nov 2022. Article
Voice Intelligence
Profiling humans from their voice
How much information can we deduce from the human voice? Currently, our work is focussed on deducing many aspects of the human persona from voice. Another facet of this work is the extraction of information from ad wit the support of multimedia that occur in the context of voice. Encompassing both facets are technologies that strive the preserve information that is specifically relevant for analysis. Some of our projects in these areas are described below.
Deducing faces from voices
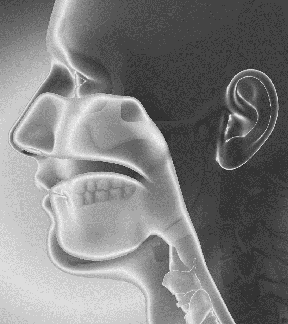
(Click all images on this page to enlarge) Sounds produced in our vocal tract resonate in our vocal chambers. They are modulated by our articulators (tongue, lips, jaw etc.) and further influenced by the structures within the vocal tract. The dimensions of our vocal chambers are highly correlated with our skull structure, which in turn defines our facial appearance to a very large extent. Many physical properties and dynamics of our vocal structures also correlate well with our age, ethnicity, height, gender and so on -- which in turn influence our appearance. Thus, it is easy to see how the signatures of many physical factors that naturally influence our voice can also directly or indirectly inform about our facial structure. Technologies that infer facial appearance and structure from voice leverage this web of information embedded in the voice signal. AI systems can also be designed to isolate this information. |
Publications
CodeApplications
First introduced in 2017, this technology made a global debut at the World Economic Forum in 2018, creating faces from voices of speakers in a VR environment. Over a thousand speakers tested it at the WEF. Some of our work was published in this book in 2019.
|
Biomarker discovery
Biomarker discovery techniques identify or design/construct specific mathematical representations of voice signals that bear a strong correlation with a particular influence hypothesized to affect voice. As an example, consider a scenario where we theorize that the consumption of a specific medication must impact the voice. Yet in practical life this does not seem to be so -- these alterations, if present, remain undetectable to us, evading even the most direct voice signal analyses. In such instances, a biomarker discovery system could reveal the precise, distinctive signature indicative of the medication's influence on a given voice signal. This distinguishing signature might lie in a complex, high-dimensional mathematical space -- an imperceptible virtual representation that is only useful for computational purposes. Nevertheless, the ability to now extract the identified signature from new voice samples allows machines to learn and detect, merely from the speaker's voice, the recent consumption of that specific medication. We began work on biomarker discovery techniques in 2016, well before the control of latent space representations using neural architectures became mainstream. Today we continue to expand the set of entities for which we have successfully created AI-based discovery pipelines. |
Publications
PatentApplicationsCurrently, multiple entities worldwide are engaged in exploring the possibilities of this technology in healthcare applications.
|
Deducing vocal fold oscillations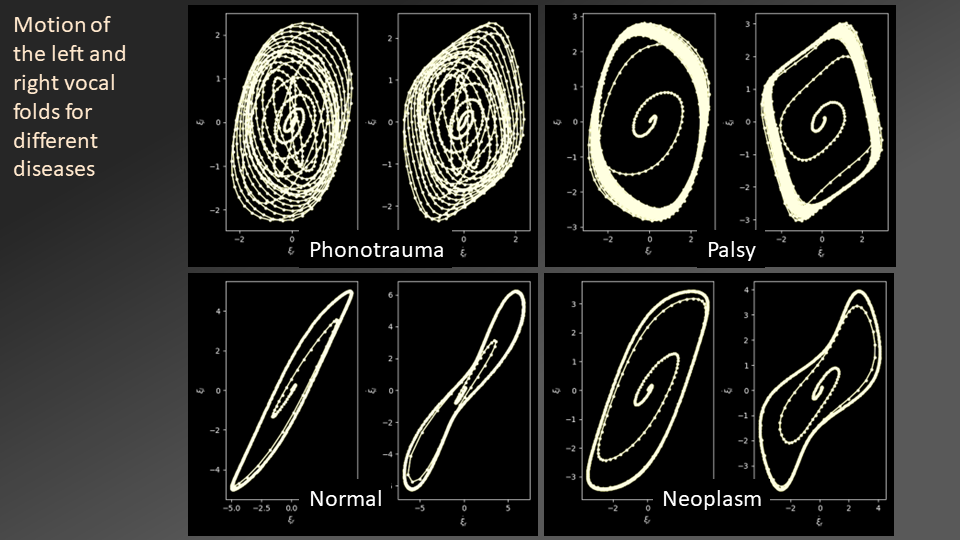
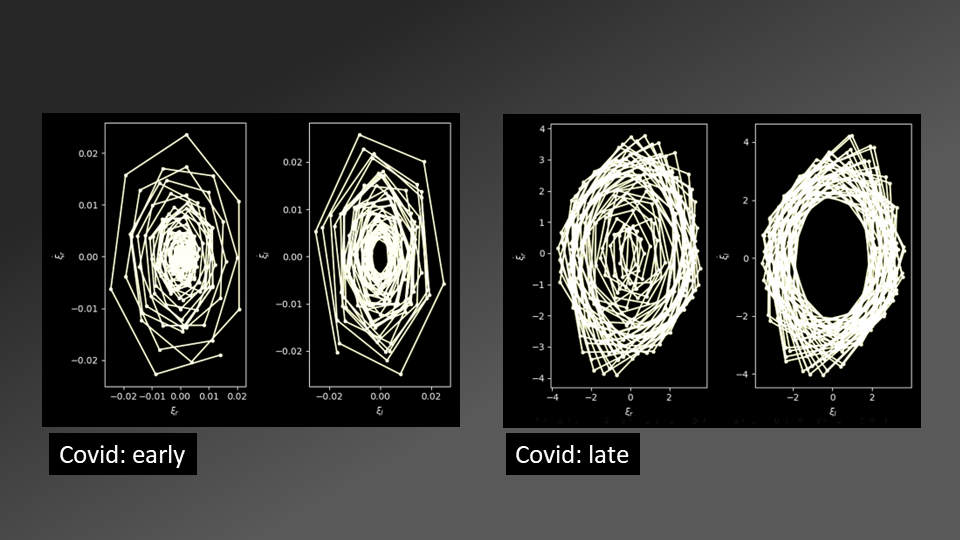
Our vocal folds oscillate in a self-sustained manner during phonation (ie, when we produce voiced sounds like a sustained "aa"). There is a wealth of information in the fine-level details of how they oscillate. Understanding these details can reveal an astonishing amount of information aboout the state of the speaker. However, historically it was hard to measure the vocal fold oscillations of each person as they spoke. Doing so required specialized instruments, to be used in clinical settings. At CVIS, we have been developing techniques to deduce the vocal fold oscillations of speakers from voiced sounds directly from recorded speech signals. This opens doors to analyzing vocal fold osciallations on an individual basis, and studying ther changes in their patterns in response to various influencing factors -- from substances to mental problems to infectious diseases like Covid-19. Based on our techniques, we built a live Covid-19 detection system in February 2020, and put together a protocol for analyzing a set of sustained vowel sounds and a couple of countinuous speech examples. This protocol is now globally used as a basis for sound analysis for Covid-19 and other conditions. We began this work in 2017 with the interesting goal of detecting voice disguise in-vacuo (without knowing what the original voice sounds like), and have made considerable progress in refining our techniques and exploring practical applications for it. |
Publications
PatentApplicationsThe most potent use of this technology is in the early detection of Parkinsons and other serious neuromuscular disorders and illnesses. With suffiencient discriminative data, this can be applied to detect a plethora of diseases, used to break voice disguise, used to differentiate synthetic speech from real, and used in many other profiling applications. |
Deducing emotional, physiological, psychological and behavioral states and traits from voice
Vocal fold oscillations are not the sole cues that offer insights into the physiological alterations within our body. Subtleties embedded within our vocal production and control (vocal expression) are also linked with our emotional, behavioral, and psychological characteristics. The deduction of such "states" from vocal nuances has been an area of considerable research, spurred by centuries of observation and correlation between speech patterns and these characteristics. Our work is two-faceted. In one, we join hands with researchers across the globe, contributing to mainstream techniques for deducing target states from voice. In the other, we move beyond these, aiming to discover the underlying traits: correlations that not only apply universally across populations but also relate specifically to an individual and their current state, and correlations with our genetic makeup. Our research aims to develop technologies to analyze diverse human states and traits, thereby enhancing our comprehension of the intricate relationship between vocal features and human characteristics. As an example, we deduce psychological traits from an aggregations of emotional states of a person -- the emotional spectrum -- and objective measurements of various voice qualities. These are also supported by measurements of low-level features. |
Publications
PatentApplications
"Creating geriatric specialists takes time, and we already have far too few. In a year, fewer than three hundred doctors will complete geriatric training in the United States, not nearly enough to replace the geriatricians going into retirement, let alone alone meet the needs of the next decade. Geriatric psychiatrists, nurses, and social workers are equally needed, and in no better supply. The situation in countries outside the United States appears to be little different. In many, it is worse." -- Quoted from Chad Boult, Geriatrics Professor, in "Being Mortal" by A. Gawande, Surgeon, and Professor at Harvard Medical School and Harvard School of Public Health.
|
Understanding personality bases
Understanding human personality plays a crucial role across numerous fields such as psychology, behavioral science, and many others. In order to understand personality, traditionally it is broken down into a handful of dimensions (or bases) like the Big-5 OCEAN traits. The way these bases have been agreed upon has been rigorous but has not been revisited for decades. In this work, we use newer AI methodologies like Large Language Models for word-base representations and K-Means and Neural Networks for understanding the underlying bases, in order to assess whether newer techniques agree with the widely accepted personality bases, and if not, what might be the optimal categorization for human personality. |
Publications
Patent
Code
ApplicationsUnderstanding personality bases has profound applications in fields such as psychology, human resources, marketing, and mental health, where accurately modeling personality can enhance decision-making and personalized interventions. Traditional frameworks like the Big-5 OCEAN traits have long provided a foundation for analyzing personality, but advancements in AI are now enabling a deeper exploration. By leveraging techniques such as Large Language Models for semantic representations and clustering methods like K-Means and Neural Networks, it becomes possible to reassess these personality bases, uncovering potentially more precise or context-specific categorizations. This evolution could lead to improved tools for tailoring education, therapy, recruitment, and even AI-human interaction, making systems and services more responsive to individual needs and traits. |
Objective measurements of voice quality and personality OCEAN traits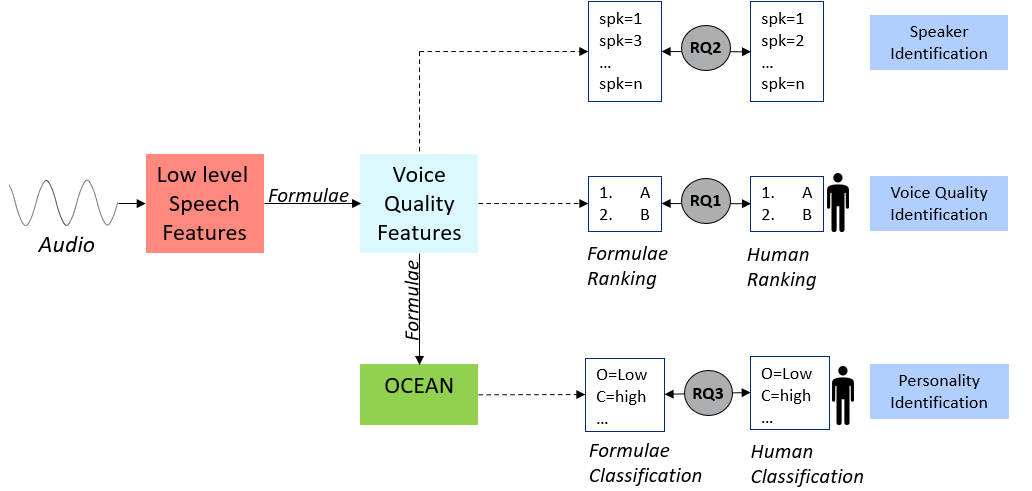
The quality of human voice plays an important role across various fields yet it lacks a universally accepted, objective definition. Despite this subjectivity, extensive research across disciplines has linked these voice qualities to specific information about the speaker, such as health, physiological traits, and others. This work aims to objectively quantify voice quality and personality by synthesizing formulaic representations from past findings that correlate voice qualities to signal-processing metrics; and based on the known correlations of voice qualities to personality OCEAN traits, devising formulae to measure OCEAN traits objectively from voice. In this work, we introduce formulae for 24 voice sub-qualities based on 25 signal properties, grounded in scientific literature, and also introduce formulae for the five OCEAN personality traits based on these 24 voice qualities, grounded in findings from past scientific studies. The soundness and correctness of voice quality and the OCEAN trait formulas are tested using various data-driven and human-expert-assessment methods. |
Publications
Patent
Code
ApplicationsObjective measurement of voice quality has wide-ranging applications across healthcare, communication, and technology. In healthcare, it can enhance the diagnosis and monitoring of voice disorders, neurological conditions, and respiratory health by identifying subtle changes in vocal parameters. In communication technologies, voice quality metrics can improve the naturalness and emotional expressiveness of text-to-speech systems, making interactions with virtual assistants and AI-driven platforms more engaging and accessible. In education, analyzing voice quality can aid in training public speakers, actors, and teachers by offering tailored feedback for voice modulation and clarity. Additionally, in security and forensics, precise voice measurements can support speaker verification and voice profiling, ensuring accurate and reliable identity authentication. This ability to objectively assess voice quality paves the way for innovations in human-computer interaction, accessibility tools, and even entertainment, where high-fidelity voice synthesis and analysis are critical. |
Preserving information in multimedia signals for analysis
Most signal intelligence and security applications process transmitted signals. Transmission channels, and the devices used for capturing audio and other multimedia signals often result in different types of attenuations, distortions and noises. Our work focuses on building the next generation AI-driven technologies for preserving information in these signals for more accurate downstream analysis. Some of this work is described below.
Benchmarking VoIP applicationsOur project on benchmarking VoIP applications is building a comprehensive performance evaluation framework tailored for businesses and developers overseeing real-time communication systems. Addressing the critical need to ensure high-quality voice transmission under varying network conditions, it assesses audio quality, latency, and system robustness against disruptions. Unlike traditional benchmarking tools that focus only on data transfer metrics, our solution incorporates AI-driven analysis of speech intelligibility, noise suppression, and speaker recognition. This differentiation ensures that your voice communications are optimized for clarity and reliability, even in the most challenging network environments. |
Publications
PatentApplications
This work finds utility across diverse domains that depend on seamless and reliable voice communication to deliver critical services, such as customer service communication, remote collaborations, media production and broadcasting etc. While these are traditional scenarios, our current work is focused on the emerging domains of voice security and intelligence, where it is ever more important to maintain crystal-clear interactions. Emergining AI-powered telehealth platforms will rely heavily on minimal-loss transmissions of voice. Early detection and mitigation of issues such as latency and jitter despite bandwidth fluctuations, will matter greatly in reliable remote automated analysis of health conditions by AI-based healthcare systems. The AI-driven speech analysis further supports industries that require voice biometrics for robust identity verification and recognition.
|
Personalized speech enhancement and separation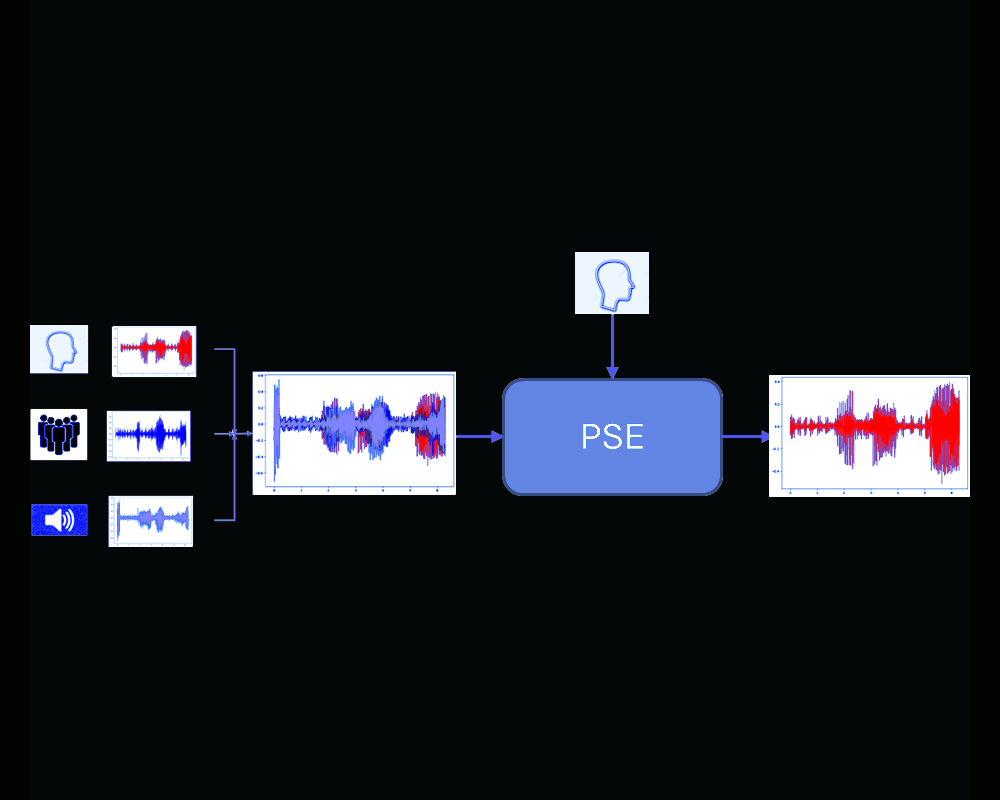
The work leverages personalized identity references—such as speaker embeddings, voiceprints, or auxiliary modalities like images, videos, or text annotations—to guide the enhancement process. These references provide crucial information about the speaker's unique vocal characteristics, including pitch, timbre, articulation style, accent etc. By incorporating these personalized features, the enhancement system ensures that the output not only suppresses blind background noise and distortions which include interfering speech, but also faithfully preserves the speaker's individuality. |
Publications
PatentApplicationsThese technologies have historically been valuable in applications like teleconferencing, assistive technologies, and virtual assistants, where maintaining a clear and distinct representation of the user's voice is critical for intelligibility and authenticity. Our enhancements to it tailor their scope to voice analysis for next generation applications such as profiling-supported interactions with embodied AI systems in natural environments, where distant speech is a norm. |
Foundation models that can comparatively analyze speakers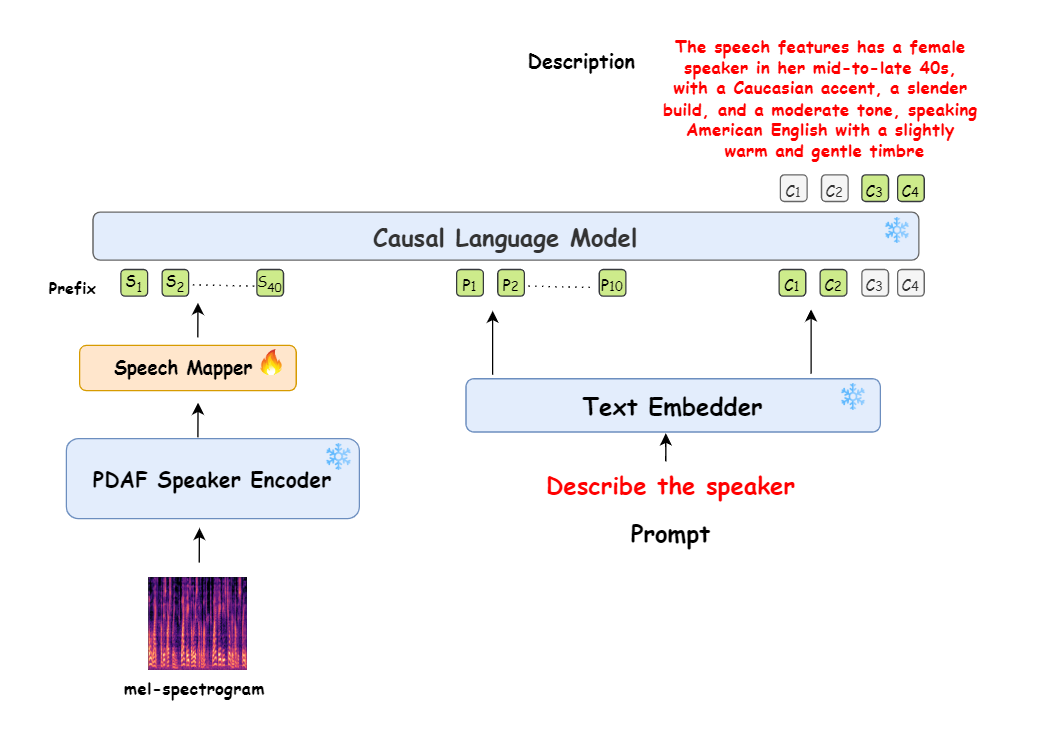
Current speaker recognition models are often costrained to basic tasks and lack the capacity to generate descriptive speaker characteristics and context-rich results. In this work we build a novel Speaker Language Model (SLM) framework that addresses these limitations by combining a speaker encoder with prompt-based conditioning. The model then generates descriptive captions for speaker embeddings, accurately capturing key attributes such as dialect, gender, and age. By utilizing user-defined prompts, the model can produce customized captions tailored to specific requirements, such as regional dialect variations or age-related characteristics. Our approach leverages the complementary strengths of language models and speaker embedding techniques, and enables the model to produce descriptions that not only capture the unique attributes of each speaker but also provide nuanced and adaptable profiling. This framework offers significant advancements in speaker recognition systems, offering enhanced descriptive profiling and adaptability across a broad range of applications. |
Publications
PatentApplicationsThese technologies have historically been valuable in applications like teleconferencing, assistive technologies, and virtual assistants, where maintaining a clear and distinct representation of the user's voice is critical for intelligibility and authenticity. Our enhancements to it tailor their scope to voice analysis for next generation applications such as profiling-supported interactions with embodied AI systems in natural environments, where distant speech is a norm. |
Audio processing
Our work on pure audio processing is described below.
Learning from imprecise labels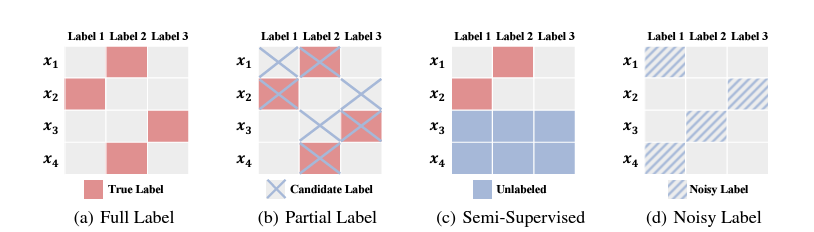

We introduce the Imprecise Label Learning (ILL) framework for audio processing, a unified approach to handle various imprecise labeling configurations, such as noisy labels, partial labels, and semi-supervised learning. By leveraging expectation-maximization (EM), ILL models imprecise label information as latent variables, enabling robust and scalable learning across diverse and mixed imprecise label scenarios, surpassing existing specialized methods. Many of the concepts in this work are easily extended to multimedia processing scenarios. |
Publications
CodeApplicationsAdvancements in computational audition, particularly in leveraging weak, semi-weak, and hierarchical labels, have broad applications across numerous fields. These techniques enable systems to analyze and interpret diverse sounds with minimal manual annotation, making it feasible to process vast amounts of web-sourced audio data. In healthcare, such systems can detect anomalies in patient environments, such as falls or distress calls, improving remote monitoring and emergency response. In smart homes, sound recognition can enhance user experience by enabling devices to respond contextually to everyday sounds. Environmental monitoring can also benefit, with systems identifying wildlife sounds or industrial noise pollution over extended periods. Additionally, robust audio segmentation and event detection methods contribute to applications in media indexing, content recommendation, and archival research, where understanding the acoustic environment is crucial. The development of a unified formalism for learning from noisy and partial labels further ensures these applications are scalable, adaptive, and capable of addressing real-world complexities. |
Framework to generate anomaly data for audio anomaly event detection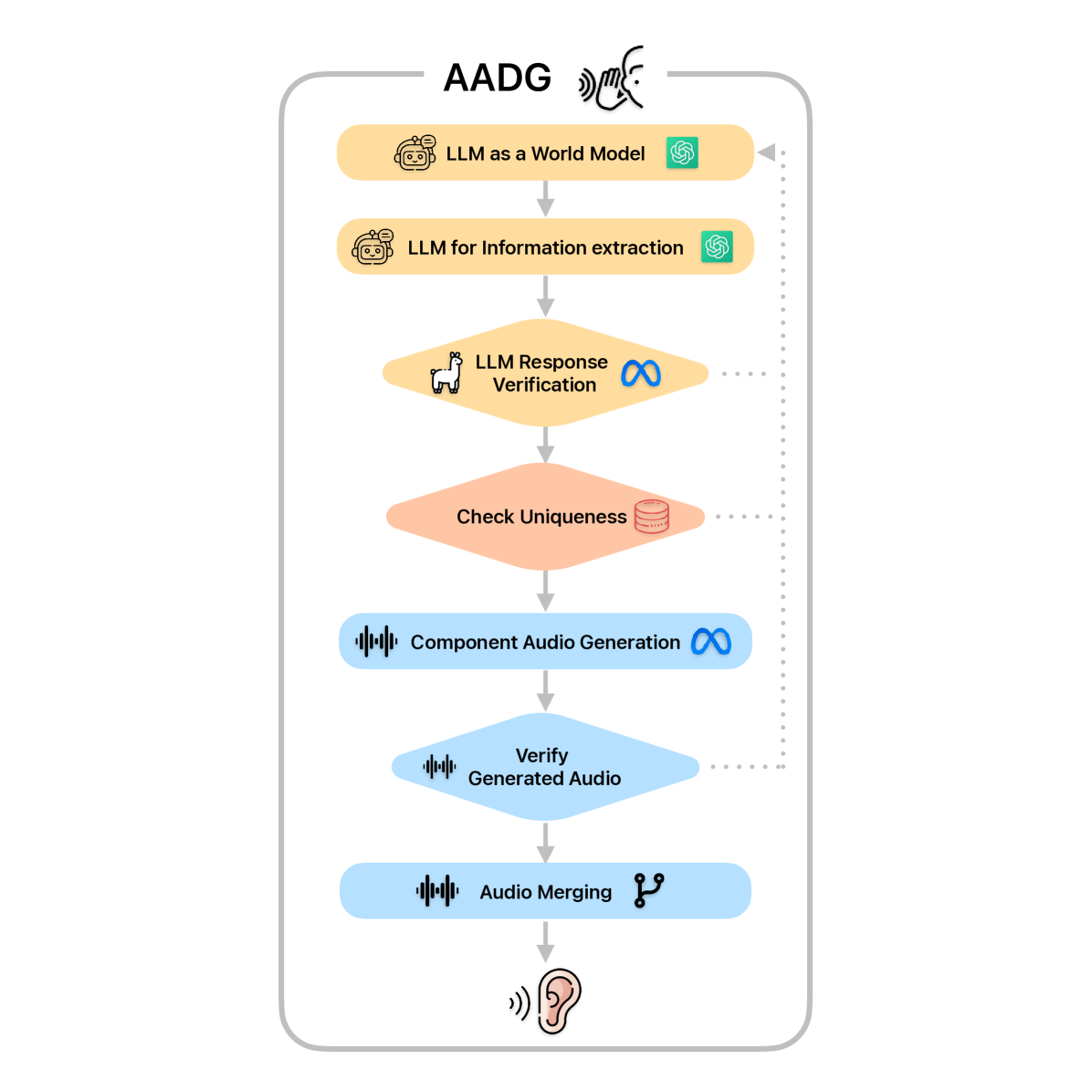
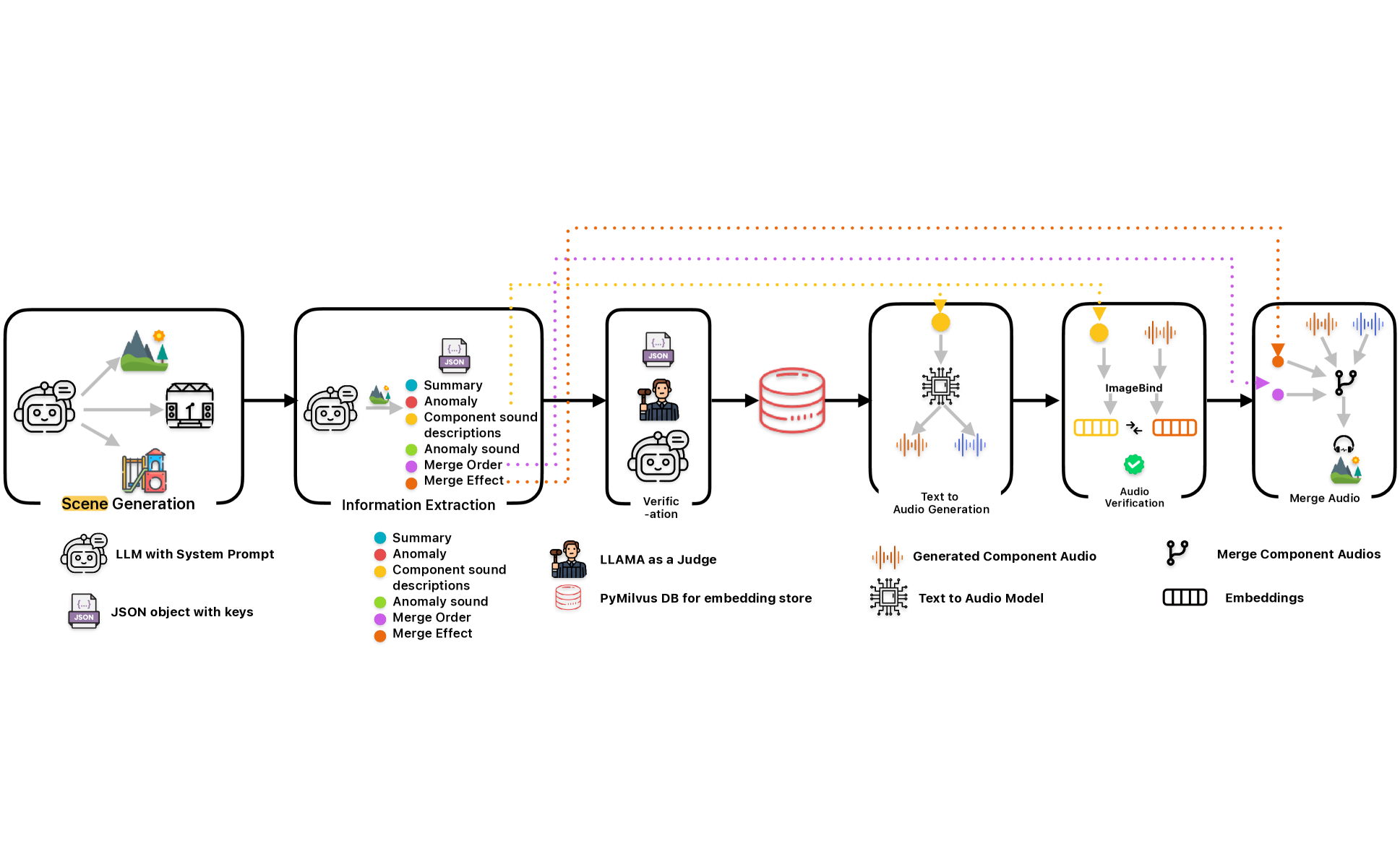
We introduce Audio Anomaly Data Generation (AADG), a framework leveraging Large Language Models (LLMs) to generate realistic audio data for anomaly detection and synthetic localization. Unlike existing datasets focusing on industrial sounds, this framework creates diverse, real-world scenarios, including anomalies, and provides a modular, scalable, and verifiable tool for generating synthetic audio data. Its impact lies in addressing the critical gap in general-purpose audio anomaly datasets, enhancing the training and benchmarking of audio anomaly detection models, and improving audio perception in safety-critical and real-world applications. |
Publications
CodeApplicationsBy generating diverse and realistic synthetic audio data, AADG supports the development and benchmarking of audio anomaly detection models, enhancing their ability to identify unusual sounds in various environments. This is particularly valuable in industrial monitoring, where detecting machine failures early can prevent costly breakdowns. It also aids in smart city infrastructure, enabling systems to recognize emergencies like car crashes or glass breaking. Additionally, AADG can improve home security systems, enhancing their ability to identify suspicious sounds, and assist in wildlife monitoring by detecting rare or unexpected animal calls. |